Research data should be submitted to institutional (UNB Dataverse), discipline-specific, community-recognized repositories where possible, or to generalist repositories if no suitable community resource is available.
The University of New Brunswick (UNB) Library provides online access to the data-sharing platform to support the RDM need of academic researchers. UNB Dataverse uses local institutional resources to store research data without outsourcing them to another location.
a platform for Canadian researchers to deposit and share research data, and to facilitate the discovery of research data in Canadian repositories. This is a collaborative project between Portage Network, CARL, and Compute Canada. FRDR utilizes Compute Canada resources to store research data as well as Globus services to transfer files and search for information. FRDR is particularly suitable for archiving and sharing large data sets (300 GB or 25,000 files).
Getting started with FRDR
To get started on FRDR demo, go to https://demo.frdr.ca/ and attempt to log in (in the header menu). From there you'll be prompted to create an account. You can use a Google, ORCID, or Compute Canada account, or you can create a new account with Globus. (Note: There is no current support logging in using the university account, but it is something that will be available in the future)
When you have an account, select the "Deposit Data" button on the FRDR demo homepage and you'll see a message asking you to email support to receive permission to use demo. (This is only the process for limited production. Once an administrator receives your email they can add you to the FRDR depositor group.)
In demo you can perform test submissions, get a sense of the metadata form to fill out, use your browser or Globus transfer to upload some test data, etc. You will need to download Globus Connect Personal to upload large datasets to FRDR using Globus, or to download large data files or entire datasets.
Some repositories on this page may only accept data from those funded by specific sources or may charge for hosting data. Be aware of any deposition policies for your chosen repository. The list includes the following disciplines and areas:
an international non-for-profit organization for archiving and sharing research data. Platform hosted data, and share data under open terms of use (for example the CC0 waiver).
re3data.org - Registry of Research Data Repositories
a global registry of research data repositories that covers research data repositories from different academic disciplines.
Dat is a peer-to-peer platform for publishing datasets both large and small. Its design borrows concepts from distributed revision control systems, allowing multiple users to contribute changes and updates to a dataset while retaining authorship information and preserving older versions. Dat was initially funded by the Knight Foundation under an initiative that "seeks to increase the traction of the open data movement by providing better tools for collaboration." The Try Dat section of the project site contains a detailed tutorial that covers creating, publishing, and updating a dataset. Reference datasets are also provided in a number of formats, including a CSV on recent earthquakes, a JSON file of recently published DOIs, and Bionode format genomics data. The tutorial covers installing Dat on Windows, macOS, and Linux. Dat is free software, distributed under the BSD license, with source code available on Github.
The infographic below will help you to make an informed decision on where to deposit your research data.
Data and code for publication
The Project Close-out Checklist for Research Data (from CalTech). The closeout checklist describes a range of activities for helping ensure that research data are properly managed at the end of a project or researcher's departure. Activities include: making stewardship decisions, preparing files for archiving, sharing data, and setting aside important files in a "FINAL" folder. (Note there is a generic, editable version with Creative Commons Attribution )
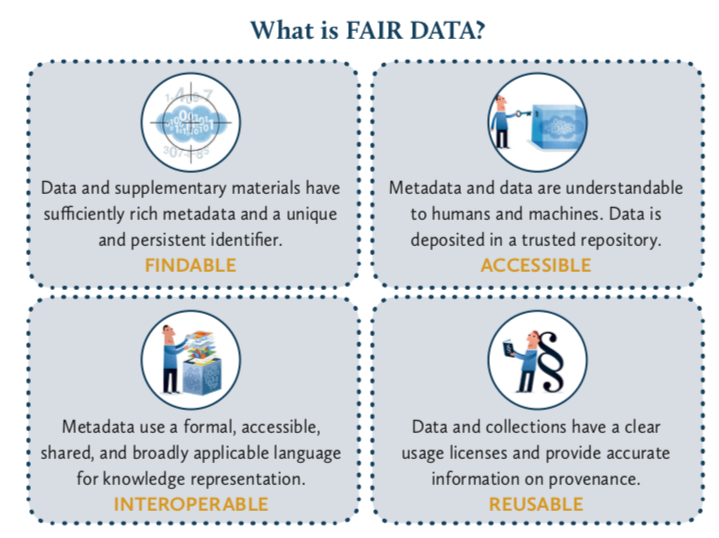
The FAIR data principles are a set of community development principles for sharing data. FAIR stands for Findable, Accessible, Interoperable, Reusable.[Association of European Research Libraries]
First, there was FAIR now there is TRUST (Transparency, Responsibility, User focus, Sustainability, Technology) (Lin, D., Crabtree, J., Dillo, I. et al. The TRUST Principles for digital repositories. Sci Data7, 144 (2020). https://doi.org/10.1038/s41597-020-0486-7; The TRUST Principles - An RDA Community Efforts.)
F-UJI is a web service to assess FAIRness of research data based on metrics developed by the FAIRsFAIR project. This website aims to demonstrate the application of the web service as a backend to implement a user-friendly web application that allows the evaluation of FAIRness of digital research data objects (aka data sets). F-UJI is a result of the FAIRsFAIR “Fostering FAIR Data Practices In Europe” project, which received funding from the European Union’s Horizon 2020 project call H2020-INFRAEOSC-2018-2020.
-this decision tree is designed to be a quick and easy-to-use guide to alert Canadian researchers to situations where research data derived from human participants either may not be shared publicly or may require some modification before sharing. It relies heavily on the Canadian Tri-Council Policy Statement: Ethical Conduct for Research Involving Humans - TCPS 2 (2018) which addresses consent and secondary use of information for research purposes.
Data and Code Availability and Provenance Statements >>>
In most cases, the terms data documentation and metadata can be used interchangeably. They help to understand raw data in details and allow other researchers to discover, use, and properly cite research data. It is important to start documenting your data at the very beginning of the research project. This could include:
making notes of all file formats, workflow details, information about how the data will be recorded and processed;
explanation of codes, variables, and abbreviations;
planning where the data will be stored in short and long terms so that other researchers can find and re-use your data.
Metadata is data about data. It is metadata that makes your research data discoverable by a search engine. Metadata, in general, contains several elements, such as:
title
creator
identifier (DOI)
date created
format
subject
funder(s)
rights/licensing
location
methodology
Metadata standards consist of elements specific to your research area or discipline. Many disciplines adapt their own metadata standards tailored to a particular needs of the research area. The diagram below shows some metadata standards
Standards-based metadata is generally preferable, but where no appropriate standard exists, writing “README” style metadata is an appropriate strategy. A README file provides information about a data file and is intended to help ensure that the data can be correctly interpreted, by yourself at a later date or by others when sharing or publishing data.
Software applications come and go. Proprietary formats created by software are typically controlled by the company and therefore might restrict the use of research data. Therefore, it is recommended to archive research data in an open source format.
A hierarchical set of controlled Earth Science vocabularies that help ensure Earth science data, services, and variables are described in a consistent and comprehensive manner and allow for the precise searching of metadata and subsequent retrieval of data, services, and variables.
Data analysis and cleanup
SPSS
A software package used for statistical analysis, which includes but not limited to descriptive statistics (cross tabulation, frequencies, descriptives, descriptive ratio statistics) and bivariate statistic (means. ANOVA, t-test, correlation). Available for Mac, Windows, and Unix. This software is available through UNB Virtual Lab for UNB students.
Advanced analytics, multivariate analyses, business intelligence, data management, and predictive analytics. SAS software licences available to UNB students from the NB-IRDTwebsite.
Free, an open source integrated development interface for R. It allows to view not only R code but also graphs, data code and the output results simultaneously. Input data could be in CSV, SPSS or SAS formats. The software is available for Mac, Windows, and Linux.
an open-source tool for transforming structured (i.e. tabular) personal data using selected methods from the broad areas of data anonymization and statistical disclosure control. It supports transforming datasets in ways that make sure that they adhere to user-specified privacy models and risk thresholds that mitigate attacks that may lead to privacy breaches. ARX can be used to remove direct identifiers (e.g. names) from datasets and to enforce further constraints on indirect identifiers. Indirect identifiers (or quasi-identifiers, or keys) are attributes that do not directly identify an individual but may together with other indirect identifiers form an identifier that can be used for linkage attacks. It is typically assumed that information about indirect identifiers is available to the attacker (in some form of background knowledge) and that they cannot simply be removed from the dataset (e.g. because they are required later for analyses). ARX also supports methods for protecting sensitive attributes from disclosure and semantic privacy models, which require fewer assumptions to be made about the goals and the background knowledge of attackers.
Sensitive data management
What is sensitive data?
The term "sensitive data" refers to data that is capable of identifying an individual, species, object, process, or location at risk of discrimination, harm, or unwanted attention. Most sensitive data cannot be shared, but there are exceptions.
An example of sensitive data is information that is protected against unwarranted disclosure. Among these are personal data, proprietary data, and other restricted or confidential information that must be protected from unauthorized access.
If you deal with sensitive data, your work might need to be overseen by UNB Research Ethics Boards (REBs). Depending on your location there are two REBs at UNB: REB Fredericton campus and REB Saint John campus. Here you can find all the necessary ethics forms with instructions on how to apply.
When conducting research that involves sensitive data or has potential for dual use, researchers may need to take additional measures to balance the need for data-sharing and access with that for protection from threats. To ensure that the integrity of their research is not compromised and research results (e.g., data sets, publications, patents) are secure and protected until they choose to disseminate them, researchers should put in place good physical and cyber security practices and infrastructure. These practices should be agreed to by all research team members and partners.
When you work with sensitive data, you will have specific management and dissemination requirements. Data that is sensitive should be password protected and encrypted and stored on a secure server with role-based access controls.
-this decision tree is designed to be a quick and easy-to-use guide to alert Canadian researchers to situations where research data derived from human participants either may not be shared publicly or may require some modification before sharing. It relies heavily on the Canadian Tri-Council Policy Statement: Ethical Conduct for Research Involving Humans - TCPS 2 (2018) which addresses consent and secondary use of information for research purposes.
The Research Ethics Boards at UNB shared the following links, which include information, forms, and guidelines:
- helps researchers determine the risk level associated with human participant research data, and decide on how to manage, deposit, and use them appropriately in the future
- this guidance document explores ethical considerations in the use of geospatial data for research, analysis and statistics. It has been developed by the UK Statistics Authority’s Centre for Applied Data Ethics in partnership with geospatial colleagues.
-this document aims to provide best practice for dealing with sensitive primary species occurrence data, and provide guidance on how to make as much data available without at the same time opening up the species to harm because data has been placed in the public domain
TCPS2 (2022) was updated on January 11, 2023. Highlights of changes are available here:
- new requirements for REB review of data repositories and new definitions/requirements for consent for data reuse
Analysis and tools for preparing sensitive data for sharing
ARX is an open-source tool for transforming structured (i.e. tabular) personal data using selected methods from the broad areas of data anonymization and statistical disclosure control. It supports transforming datasets in ways that make sure that they adhere to user-specified privacy models and risk thresholds that mitigate attacks that may lead to privacy breaches. ARX can be used to remove direct identifiers (e.g. names) from datasets and to enforce further constraints on indirect identifiers. Indirect identifiers (or quasi-identifiers, or keys) are attributes that do not directly identify an individual but may together with other indirect identifiers form an identifier that can be used for linkage attacks. It is typically assumed that information about indirect identifiers is available to the attacker (in some form of background knowledge) and that they cannot simply be removed from the dataset (e.g. because they are required later for analyses). ARX also supports methods for protecting sensitive attributes from disclosure and semantic privacy models, which require fewer assumptions to be made about the goals and the background knowledge of attackers.
Amnesia is a free data anonymization tool that transforms relational and transactional databases into a dataset where formal privacy guarantees hold. In Amnesia, direct identifiers like names are removed and secondary identifiers like birth dates and zip codes are transformed to prevent individuals from being identified. Amnesia supports k-anonymity and km-anonymity.
Indigenous research
If your research engages with or involves Indigenous peoples, be aware of and consider your obligations under the RDM policy and ethical guidelines, including best practices and requirements for conducting Indigenous research as outlined in Tri-Agency frameworks and institutional policies, as applicable. The Tri-Agency strongly recommends co-developing a data management plan (DMP) in close partnership with Indigenous communities, respecting data sovereignty and using the guiding principles - CARE and OCAP. The DMP is considered a 'live document' which may be revised as the project takes shape and data begins to flow in, but it is critical to start developing it early in the research process.
The McMaster DMPs Database, is a collection of over 400+ DMPs across many disciplines. Enter the keyword 'Indigenous' into the search bar to retrieve several examples of publicly available DMPs of research involving Indigenous peoples.
Definition
Traditional Knowledge / Indigenous Sensitive Data:
The knowledge held by First Nations, Inuit and Métis peoples, the Aboriginal peoples of Canada. Traditional knowledge is specific to place, usually transmitted orally, and rooted in the experience of multiple generations. It is determined by an Indigenous community’s land, environment, region, culture, and language. It may also be new knowledge transmitted to subsequent generations. (source: Sensitive Data Toolkit For Researchers)
Data Sovereignty
Indigenous Data Sovereignty is the right of Indigenous peoples to control data from and about their lands and communities, as well as data created with or about them. It recognizes Indigenous people as the ultimate authorities on their data and knowledge, and it aims to redefine Indigenous peoples' relationship to research from being participants or subjects to being meaningful partners and co-researchers.
"... what indigenous peoples are seeking is a right to identity and meaningful participation in decisions affecting the collection, dissemination and stewardship of all data that are collected about them. They also seek mechanisms for capacity building on their own compilation of data and use of information as a means of promoting their full and effective participation in self-governance and development planning" (Taylor, J., & Kukutai, T. (2016). Indigenous data sovereignty: Toward an agenda.)
Guiding Principles
OCAP is a set of principles defined by the First Nations Information Governance Centre (FNIGC), which asserts the need for First Nations communities to have ownership, control, access, and possession of data involving them.
CARE is an overarching set of principles highlighting the need for research involving Indigenous communities to have collective benefit, while the communities themselves have the authority to control their data, with the goal of conducting responsible and ethical research. Introduced by the Global Indigenous Data Alliance (GIDA) to preserve and manage First Nations data.
"The current movement toward open data and open science does not fully engage with Indigenous Peoples rights and interests. Existing principles within the open data movement (e.g. FAIR: findable, accessible, interoperable, reusable) primarily focus on characteristics of data that will facilitate increased data sharing among entities while ignoring power differentials and historical contexts. The emphasis on greater data sharing alone creates a tension for Indigenous Peoples who are also asserting greater control over the application and use of Indigenous data and Indigenous Knowledge for collective benefit. This includes the right to create value from Indigenous data in ways that are grounded in Indigenous worldviews and realize opportunities within the knowledge economy. The CARE Principles for Indigenous Data Governance are people and purpose-oriented, reflecting the crucial role of data in advancing Indigenous innovation and self-determination. These principles complement the existing FAIR principles encouraging open and other data movements to consider both people and purpose in their advocacy and pursuits." (CARE Principles for Indigenous Data Governance)
Other community-specific resources may be available as they relate to your research. Connecting with Indigenous communities and consulting resources early will help to ensure your project incorporates best practices relating to Indigenous data sovereignty from the start.
The Agencies recognize that data related to research by and with Indigenous communities must be managed in accordance with data management principles developed and approved by these communities. These include, but are not limited to considerations of data collection, ownership, protection, use and sharing. The principles of ownership, control, access and possession (OCAP®) are one model for First Nations data governance, but this model does not necessarily respond to the distinct needs and values of distinct First Nations, Inuit and Métis communities.
With respect to Indigenous research, the agencies acknowledge the importance of ethical considerations and refer grant recipients to the framework for the ethical conduct of research involving First Nations, Inuit, and Métis Peoples outlined in Chapter 9 of the Tri-Council Policy Statement: Ethical Conduct for Research Involving Humans (TCPS 2). Decisions to deposit and/or share Indigenous research data and knowledge should be guided by principles of research with Indigenous Peoples.
Moving forward, the agencies plan to support the development of Indigenous RDM protocols that aim to ensure community consent, access and ownership of Indigenous data, and protection of Indigenous intellectual property rights. This next phase in advancing Indigenous RDM in Canada is outlined in Strengthening Indigenous research capacity.
Many journals require authors to include a Data Availability Statement (DAS), which tells the reader if the data behind a research project can be accessed and, if so, where and how. Normally a DAS is included in a very visible place in the manuscript right before the reference section.
Check the Author Guidelines section of the journal's website for specific instructions. Most journals offer templates for different kinds of DAS formats regarding different means of accessing data (or not). If data are confidential due to ethical, legal, or privacy concerns, your should still provide a DAS but indicate any restrictions. When specific journal instructions regarding how to formulate a DAS are absent or unavailable, there are some examples below you might find handy. However, you should consider tailoring or combining them to fit your needs.
Data available to be shared
The raw data required to reproduce the above findings are available to download from [INSERT PERMANENT WEB LINK(s)]. The processed data required to reproduce the above findings are available to download from [INSERT PERMANENT WEB LINK(s)].
Data NOT available to be shared
The raw/processed data required to reproduce the above findings cannot be shared at this time due to legal/ ethical reasons.
The raw/processed data required to reproduce the above findings cannot be shared at this time due to technical/ time limitations.
The raw/processed data required to reproduce the above findings cannot be shared at this time as the data also forms part of an ongoing study.
When collecting, using, or sharing Indigenous research data, specific considerations and protocols need to be taken into account. As Tri-Agency is still working on framing Indigenous RDM protocols, one practical example can be considered as developed by the UBC Library - Tools for Digitizing and Sustaining Indigenous Knowledge:
- First Nations Subject Headings (A working document from the Xwi7xwa Library, University of British Columbia that combines Xwi7xwa, Library of Congress, and other subject headings)
When sharing Indigenous data, make sure a clear statement about acceptable or appropriate secondary use or reuse of data and any restrictions on data accessibility is included.
A free and open-source platform for managing and sharing digital cultural heritage built with Indigenous communities is:
(Campbell, S., Dorgan, M., & Tjosvold, L. (2014). Creating Provincial and Territorial Search Filters to Retrieve Studies Related to Canadian Indigenous Peoples from Ovid MEDLINE. Journal of the Canadian Health Libraries Association Journal De l’Association Des bibliothèques De La Santé Du Canada, 35(1), 5–10. https://doi.org/10.5596/c14-010)
CARE principles for Indigenous Data Governance (Collective benefit, Authority to control, Responsibility, and Ethics = CARE)
Carroll, S. R., Herczog, E., Hudson, M., Russell, K., & Stall, S. (2021). Operationalizing the CARE and FAIR Principles for Indigenous data futures. Scientific Data, 8(1), Article 1.https://doi.org/10.1038/s41597-021-00892-0
NIKLA - National Indigenous Knowledge and Language Alliance. (2022). Projects. National Indigenous Knowledge and Language Alliance.https://www.nikla-ancla.com/projects
Mukurtu- free and open-source platform built with Indigenous communities to manage and share digital cultural heritage. https://www.mukurtu.org/
Data management plan
What is a data management plan (DMP)?
A DMP is a document outlining how you handle (organize, store, and share) your research data both duringthe projectand afterthe project is completed.
If your research engages with or involves Indigenous communities in any way, be aware of and consider your obligations under the RDM policy and ethical guidelines, including best practices and requirements for conducting Indigenous research as outlined by Tri-Agency frameworks and, as applicable, institutional policies. Ideally, a data management plan should be co-developed with the Indigenous communities that your research involves.
Some notable guiding principles and resources that you may find useful to refer to include:
CARE, an overarching set of principles highlighting the need for research involving Indigenous communities to have collective benefit, while the communities themselves have the authority to control their data, with the goal of conducting responsible and ethical research
OCAP, a set of principles set forth by the First Nations Information Governance Centre (FNIGC) which asserts the need for First Nations communities to have ownership, control, access, and possession of data involving them.
Other community specific resources may be available as they relate to your research. Connecting with Indigenous communities and consulting resources early will help to ensure your project incorporates best practices relating to Indigenous data sovereignty from the start.
Responsibilities & resources:
Consider who will be responsible for various aspects of research data management, including such things as data collection and/or acquisition, analysis, storage and security, and long-term data stewardship. Depending on your project’s needs, responsibilities may be assigned to specific individuals or be shared, including by the principal investigator, co-investigators, research staff, trainees, another individual, or an organization.
You should also consider what resources may be required in order to meet your project’s data management needs, including if dedicated positions or outsourcing of tasks is required, and how these costs will be met. Building data management support into your research budget will help to ensure that your project’s needs are met.
A Digital Object Identifier or a DOI (DOI System) is a unique persistent identifier for a published digital object such as book, article, study or dataset. The word 'persistent' means that it never changes. The idea behind a persistent identifier is that it doesn't break when a website gets updated.
How to obtain a DOI for data set?
A DOI can be created by publishing organizations, not by individual people. Many data repositories can publish research data and assign a DOI to a data set. This data DOI can then be used to cite your data set in a publication. View the list of data repositories to choose which one is more appropriate for the type of data you deal with and carefully read their Terms and Conditions as some repositories may charge you for using their services.
Here is a list of selected data repositories where a DOI can be assigned free of charge to a dataset:
By properly citing the data and including the DOI, you're giving proper credit to the creators who conducted the research and providing the scholarly community a clearer picture of the impact of the research.
APA 6th edition:
Refer to Publication Manual of the American Psychological Association, 6th edition, (2010)p 210 - 211 (datset) and p 212 (unpublished raw data) [UNB Library: BF76.7 .P83 2010b; OCLC:316736612].
APA Style Guide to E- Resources:
Refer to APA Style Guide to Electronic References (2012) [UNB Library: PN 171 .F56 A63 2007 ; OCLC:795354092].
->> Data set:
Author. (Year). Title of data set (version number). Location: Name of the creator.
or
Author. (Year). Title of data set (version number). Retrieved from http://
->> Raw data (unpublished, untitled work):
Author. (Year). [Description of study topic]. Unpublished raw data.
UNB Dataverse: Data Deposit Procedure
Fill out an online Data Deposit Request Form. Once submitted, this form will be send to UNB's RDM Services and one of the librarians will respond to your request.
Meanwhile ...
if you deposit dataset for the first time, go to UNB Dataverse page, click Log In, select University of New Brunswick, and click Continue. The admin will activate your account and assign a role.
For training on using UNB Dataverse, please contact RDM Services at rdm.services@unb.ca
This book is an edited collection based on a seven-session national forum webinar series on data quality literacy. It covers topics including evaluating data quality: challenges & competencies, quality assurance in data creation, understanding & evaluating governmental data (U.S. & International), commercial data quality issues, data quality: reproducibility and preservation, data quality: evolving employer expectations, and librarians’ role in cultivating data-literate citizens.
Research Data Management (RDM) is an emerging service at UNB Libraries, focused on providing support for data management planning, storing, and publishing. RDM is an increasingly important part of research and scholarly communications. Our website is currently under construction. We work on creating content and services relevant to our research community. Please contact RDM Services for details and/or to ask what we have to offer.
A free online course with all you need to know for research data management, along with ways to engage and share data with business, policymakers, media, and the wider public.
The self-paced training course will take 15 to 20 hours to complete in eight structured modules. The course is packed with videos, quizzes, and real-life examples of data management, along with valuable tips from experts in data management, data sharing, and science communication.
A registry for online learning resources focusing on research data management. It was created in a collaboration between the U.S. Geological Survey's Community for Data Integration, the Earth Sciences Information Partnership (ESIP), and DataONE.
Data Carpentry develops and teaches workshops on the fundamental data skills needed to conduct research. Their mission is to provide researchers with high-quality, domain-specific training covering the full lifecycle of data-driven research.
This instance of The Art of Literary Text Analysis is created in Jupyter Notebooks based on the Python scripting language. Other programming choices are available, and many conceptual aspects of the guide are relevant regardless of the language and implementation.
HDSI combines features of a premier research journal, a leading educational publication, and a popular magazine, HDSR provides a centralized, authoritative, and peer-reviewed publishing community to service the growing profession.
RDM costing tools for grant proposals
What will it cost to manage and share my data? (from OpenAIRE) Infographics provide information for researchers on the costs of research data management, how these can be addressed in advance, and the community resources available.
Want to estimate the RDM cost for your research project? This tool is for you.